| 모델 비종속적 설명 (Model -agonistic; 블랙박스에 대한 귀납적 추론 기반) |
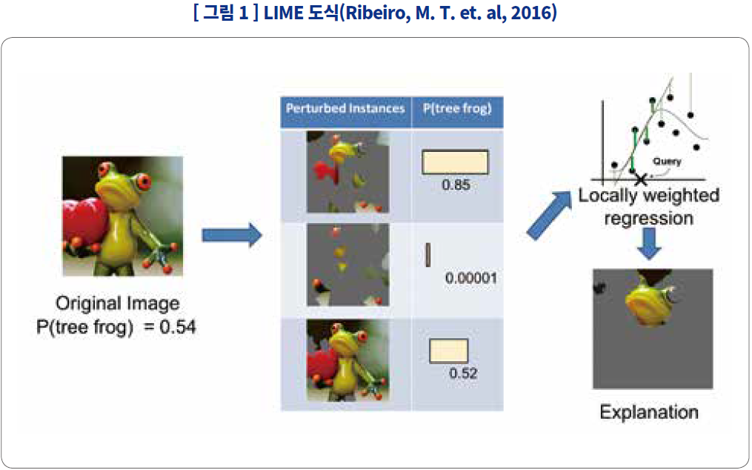
LIME |
모델과 무관하게 입력과 출력만으로 확인 가능(모델 공개가 되지 않을 때 비교적 유용한 접근법이며 대리모델 기반 방법론이 공유하는 장점), 특정 샘플에 대해 설명이 쉬워 실무에 적합 |
설명 단위가 그때그때 달라짐, 입력과 출력만을 간접적으로 설명할 뿐 인공지능 모델에 대해 설명하지 않으므로 모델의 본질을 설명할 수 없음 |
| 모델 종속적 설명 (Model -specific; 매개변수, 아키텍쳐에 대한 지식 기반) |
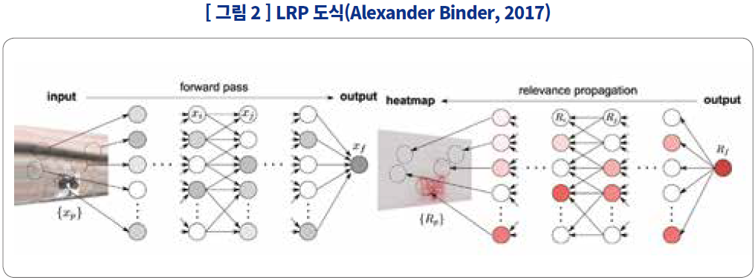
LRP |
직관적이며 은닉층 내부의 기여도를 확인할 수 있어, 해당 은닉층이 뭘 감지했는지 알아볼 수도 있음 |
기여도를 히트맵으로 표현하는 것으로는 신경망 모델이 학습한 추상적인 개념을 알 수 없음 |
| Explorative Sampling Considering the Generative Boundaries of DGNN |
복잡한 생성 모델에 쓰인 격자의 성격을 각 격자 사이에 있는 샘플들을 통해 어림짐작 가능 |
여러 샘플을 보고 판단하는 과정에서 모호한 변화와 이를 나누는 경계를 언어로 표현하기 어렵거나, 표현해도 예제 기반 설명의 특성상 분석가의 편향이 개입될 수 있음 |
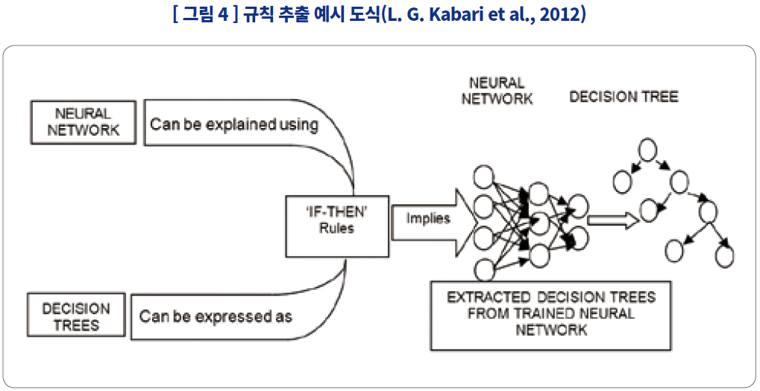
| Rule extraction |
신경망을 이해하기 쉬운 Decision Tree 순서도 형식으로 변형 |
신경망 모델을 축약하는 과정에서 모델의 정보를 누락 할 수밖에 없음 |
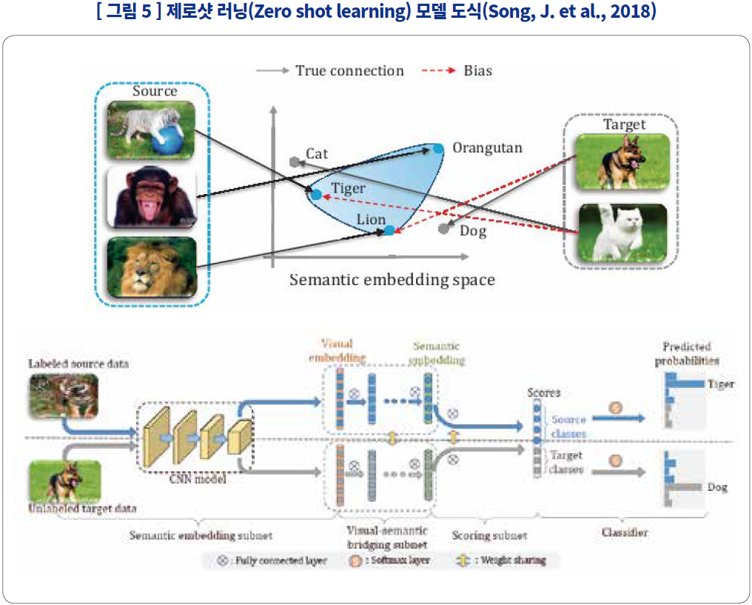
| Zero shot learning |
기존의 분류에 없는 데이터를 판단하는 과정에서 그에 대응하는 텍스트에 맞춰 분류하므로 지식 그래프에 기반한 설명이 가능함. |
데이터에 대응하는 데에 사용한 지식 그래프에 따라 설명의 수준이 결정되며, 지식 그래프 만드는 데 쓰인 모델을 설명하지는 않음 |